Resources
Featured Content


















































See M-Files in Action
Seeing is believing. Schedule a demo to learn more about simplified search, automatic workflows,intutive user interfaces, and built-in integrations with existing applications and file systems.

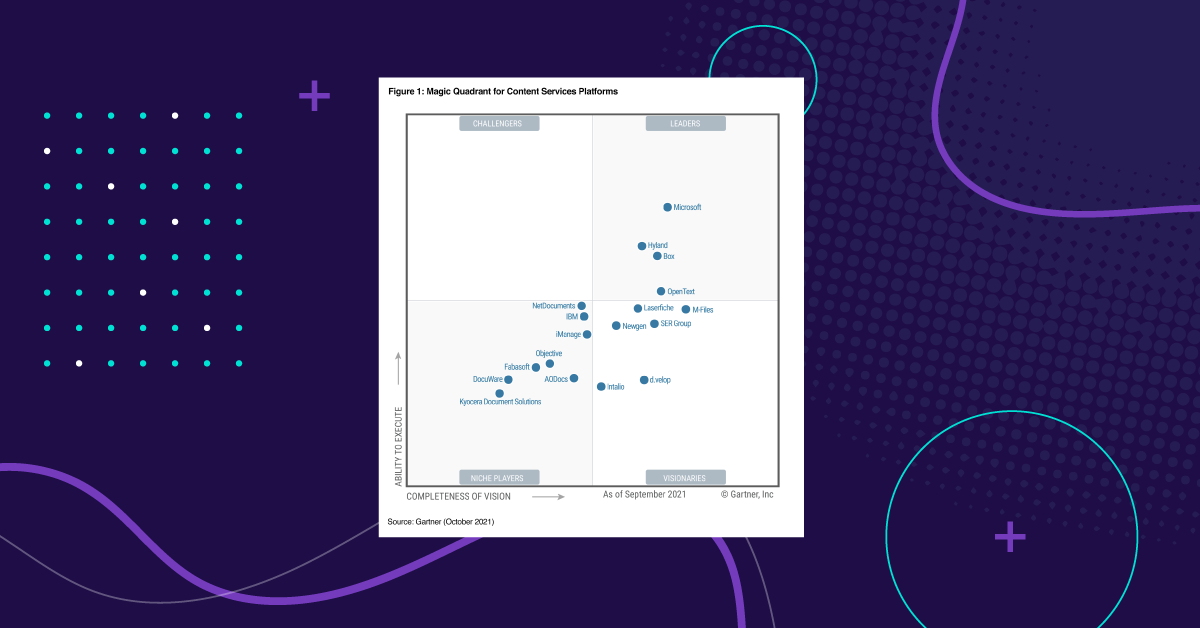




Case Studies

Case Studies
Washington University Investment Management Company
With M-Files, Washington University Investment Management Company has been able to streamline their document processing and improve oversight, consistency, and reliability in their operations.

Case Studies
FVCbank
Find out how FVCbank was able to automate their processes, achieve time savings and improve collaboration while taking care of security and compliance by implementing M-Files.

Case Studies
HUMANEXX & Hanselmann
To bring digital transformation to its document-management processes, HUMANEXX turned to Hanselmann & Compagnie, an M-Files partner, to develop a new solution for the digital management of personnel records using the M-Files knowledge work automation platform.

Case Studies
TTI, Inc. – Europe
With its success in sales processes, customs clearance, and quality management, M-Files has established itself as a central platform at TTI, Inc. - Europe.

Case Studies
Van Rhijn Bouw
Find out how Van Rhijn Bouw works with M-Files to build a solid foundation for Information Management.

Case Studies
Schera
Learn how the centralized management provided by M-Files allows Schera to easily and immediately find all accounting information, process workflows, and automate filing.

Case Studies
ello communications
With M-Files, ello communications is able to be more efficient every day and provide better value for customers.

Case Studies
St Paul’s Collegiate School
Learn how M-Files helped St Paul's Collegiate School to digitize records management and efficiently organize & access records.

Case Studies
Syntal
With M-Files, Syntal is able to quickly search for specific documents and locate any information as it is needed.

Case Studies
Indara
With M-Files, Indara achieved contract compliance, improved efficiency & customer service and reduced costs & risks.

Case Studies
Farmers Trading Company
By deploying M-Files, Farmers’ HR advisors could easily process payroll and review documents anywhere, any time.

Case Studies, Video Case Studies, Videos
Innisfree
Innisfree leveraged the power of metadata, combined with a smooth onboarding process and an easy-to-use interface to improve document management.

Case Studies
HL Technology
Learn how HL Technology created a digitalization strategy for production orders as well as automated their quality management system using M-Files.

Case Studies
Posti
By using M-Files, Posti can navigate through any future changes in business data trends, digital practices, new rules and regulations.

Case Studies
DUO Collection
Learn how digitalization using M-Files paved the way for greater transparency and efficiency for DUO Collection.

Case Studies
Charles River Laboratories
Charles River Laboratories streamlines process automation with M-Files, resulting in millions in cost savings.

Case Studies
Valeo Financial Advisors
M-Files allows Valeo to centrally manage and update document templates, so advisors spend more time on delivering their clients goals.

Case Studies
Freeze-Dry Foods
Freeze-Dry Foods unfreezes document management obstacles with M-Files.

Case Studies
Newman Women’s Shelter
Newman Women’s Shelter uses M-Files to streamline their office, freeing up staff resources to better serve the community.

Case Studies
HEB Construction
HEB Construction streamlines processes and data across diverse sites with M-Files.

Case Studies
Norco Co-operative Limited
Norco automates AP, HR, POD and Food Compliance processes and creates the opportunity for future efficiencies with M-Files.

Case Studies
Kavanagh
Kavanagh recognized that M-Files was the appropriate solution to meet its business goals.

Case Studies
Banijay
Learn how M-Files Ment allowed Banijay to create contracts faster and with greater compliance.

Case Studies
Natsure
Insurance company uses M-Files to streamline processes and saves $100K in annual salary costs.

Case Studies
vem.die arbeitgeber
Learn how M-Files document management transformed NCR&E operations by centralizing document storage resulting in anywhere accessibility of customer data.

Case Studies
Hotel Schweizerhof Bern Ag
Today, every document at Hotel Schweizerhof is stored in M-Files and all departments benefit from an enormous simplification in daily business through intelligent information management.
Case Studies
IKM Ocean Design
Thanks to M-Files, IKM management has a better overview of the business making it easier to plan for the future as well.

Case Studies
Crowe UK
Having experienced significant growth, Crowe UK required more support from its technology infrastructure with the M-Files approach.

Case Studies
Anderson Construction Ltd
New Zealand construction company achieves auditability and streamlined operations with M-Files document management system.

Case Studies
Federal Realty
Federal Realty manages dozens of top-tier properties across the country with M-Files' help.

Case Studies
Burra Foods Australia
M-Files enabled Burra Foods to halve the time it takes for its staff to manage documents, be fully compliant with its incidence management, and deliver transparent collaboration.

Case Studies
E tū Union
Discover how M-Files helped a leading union in New Zealand boost collaboration and minimize business and compliance risks.

Case Studies
Himmelwright, Huguley & Boles
Himmelwright, Huguley & Boles' clients now has instant, secure access to client tax information and can upload new content directly to M-Files.


Case Studies
Newsec
Learn how Newsec leverages M-Files EIM capabilities as a centralized solution for their asset management, CRM and ERP needs.

Case Studies
ETHRA
Find out how a non-profit organization all but eliminated paper and greatly improved efficiency in processes and compliance.

Case Studies
Wijbenga
Learn how Wijbenga B.V., a specialist in cooling tech from the Netherlands, uses M-Files document management for managing all of it's customer projects documentation.

Case Studies
Vigor Works
Vigor, an industrial services firm, leverages M-Files for quality and compliance management as well as to manage nuclear contacts and project documentation.


Case Studies
TEAM Industrial Services
Discover how TEAM turned to M-Files for help creating a new document control system which established remote access to procedures and safety documents for its technicians in the field.

Case Studies
Tampere Adult Education Center TAKK
Learn how TAKK addressed content chaos by selecting the M-Files enterprise information system.

Case Studies
Stearns Bank
To support corporate growth, Stearns Bank turned to M-Files for a centralized, easy-to-use document management system.

Case Studies
SRSI
SRSI leveraged M-Files to transition from paper to electronic document management, and as a result has reduced file processing times while also optimizing employee collaboration and automating hiring procedures.

Case Studies
Southern Hills Title
Discover how M-Files document management software helped Southern Hills Title to replace paper-based administration processes with a digital solution that allowed employees to efficiently find, manage and share confidential files internally and with approved third parties.

Case Studies
Austbrokers Countrywide
M-Files showcases its document management in a case study to show how insurance businesses can improve customer focus, streamline processes and grow.

Case Studies
SATRA Technology
In this case study discover how SATRA Technology leverages M-Files to transform and optimize business processes and quality management.

Case Studies
Roal
M-Files hybrid cloud deployment for quality management & document management helped biotech manufacturing company improve processes & customer satisfaction.





















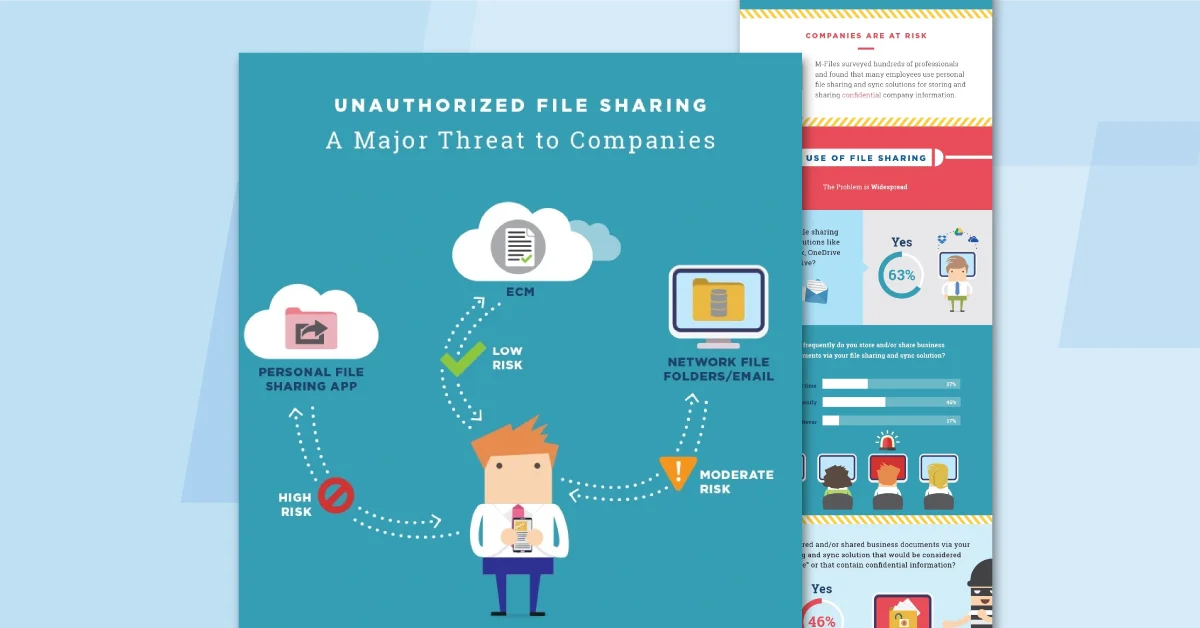















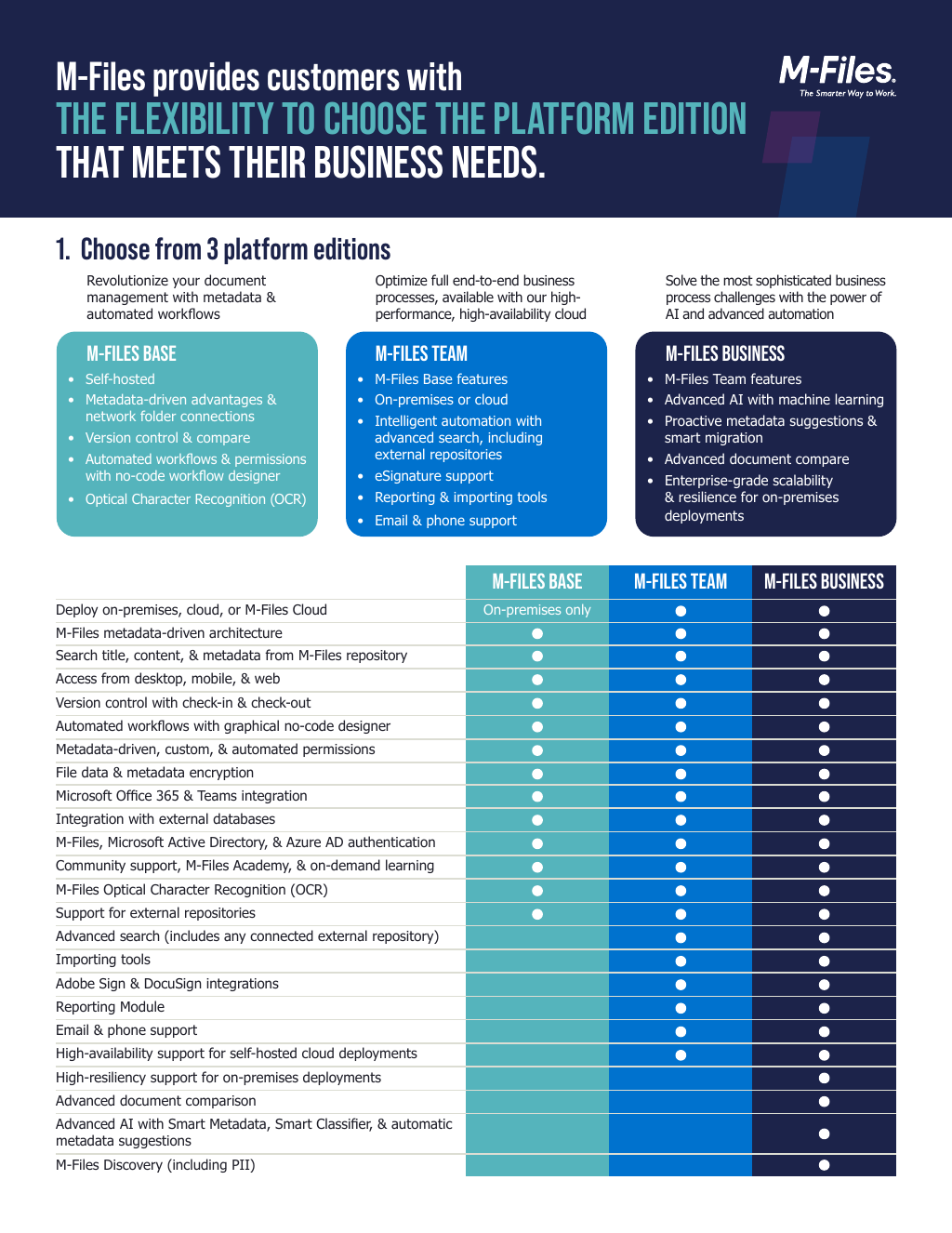
See M-Files in Action
Seeing is believing. Schedule a demo to learn more about simplified search, automatic workflows,intutive user interfaces, and built-in integrations with existing applications and file systems.













































Videos & Podcasts
Case Studies, Video Case Studies, Videos
Innisfree
Innisfree leveraged the power of metadata, combined with a smooth onboarding process and an easy-to-use interface to improve document management.












































See M-Files in Action
Seeing is believing. Schedule a demo to learn more about simplified search, automatic workflows, intuitive user interfaces, and built-in integrations with existing applications and file systems.