Définir une source de valeur OCR
Vous pouvez extraire du texte ou des codes-barres à partir d’un document numérisé à l’aide de la reconnaissance optique de caractères (OCR) et vous en servir en tant que valeurs de propriétés automatiques pour les fichiers importés à partir d’une source externe, un scanner dans le cas présent. La source de valeur OCR est une zone définie sur une page numérisée. Pour de plus amples renseignements sur la façon de définir les différentes propriétés pour les objets importés à partir de sources de fichiers externes, consultez Définition des métadonnées pour une source de fichier externe.
- TIF
- TIFF
- JPG
- JPEG
- BMP
- PNG
L'utilisation de la source de valeur OCR est uniquement possible dans le cas de l'utilisation d'une source externe. La source de valeur OCR ne peut pas être définie dans M-Files Desktop.
Effectuez les étapes suivantes pour définir une source de valeur OCR :
-
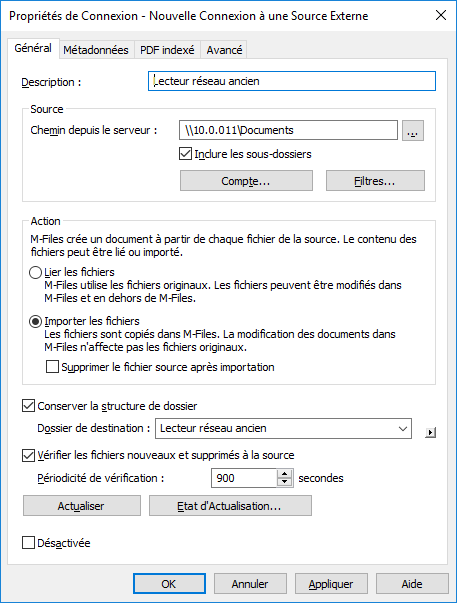
Dans la liste Fichiers, double-cliquez sur le fichier que vous souhaitez modifier.
Résultat :La boîte de dialogue Propriétés de Connexion s’ouvre.
-
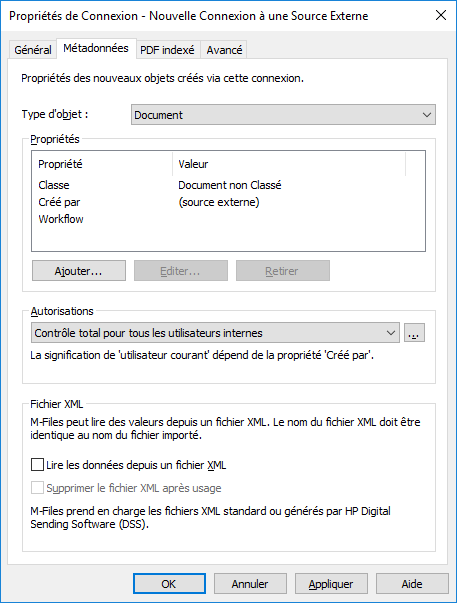
Cliquez sur l’onglet Métadonnées.
Résultat :L’onglet Métadonnées s’ouvre.
-
Cliquez sur Ajouter... pour définir une nouvelle propriété et valeur à ajouter automatiquement aux objets créés à partir de fichiers externes ou sélectionnez l’une des propriétés existantes et cliquez sur Editer... pour modifier la propriété existante.
Résultat :La boîte de dialogue Définition de la Propriété s’ouvre.

-
Sélectionnez l’option Utiliser une source de valeur OCR et cliquez sur le bouton Définir....
Résultat :La boîte de dialogue Définition d'une source de valeur OCR s’ouvre.

-
Dans la rubrique Position de la zone, définissez une zone à partir de laquelle extraire une valeur pour la propriété sélectionnée. Les caractères peuvent inclure de nombreuses lettres, chiffres ou caractères de ponctuation. Par exemple, un numéro de facture affiché sur une page peut être ajouté comme la valeur de la propriété Numéro de facture du document numérisé.
Si vous capturez un code-barres et qu'il y a seulement un code-barres à reconnaître dans la page, vous pouvez spécifier toute la page en tant que zone. Si plusieurs codes-barres sont présents, limitez la zone de telle sorte qu'elle contienne seulement le code-barres souhaité. S'il s'agit de codes de type QR, vous devez spécifier une zone plus grande que le code-barres. Si la zone spécifiée contient plusieurs codes-barres, tous sont considérés comme une valeur de propriété.
- Dans le champ Page, saisissez le numéro de page du document numérisé que vous souhaitez utiliser en tant que source de valeur OCR.
- À l’aide de l’option Unité, sélectionnez l’unité appropriée pour définir la position de la zone.
- Dans le champ Gauche, saisissez la position du coin gauche de la zone OCR. Le coin gauche du document numérisé est considéré comme "0".
- Dans le champ Droit, saisissez la position du coin droit de la zone OCR.
- Dans le champ Supérieur, saisissez la position du coin supérieur de la zone OCR. Le coin supérieur du document numérisé est considéré comme "0".
- Dans le champ Inférieur, saisissez la position du coin inférieur de la zone OCR.

Pour s'assurer que la zone spécifiée est correctement positionnée, dans la plupart des cas, le document à numériser doit être placé à la main sur la vitre du scanner.
Dans certains cas, l’OCR peut proposer un résultat de reconnaissance du texte incorrect. Par exemple, en fonction du type et de la taille de la police, le chiffre 1 peut être interprété comme la lettre I. Pour s'assurer que les caractères sont correctement ajoutés aux métadonnées, vous pouvez vérifier les valeurs de propriété à l'aide de gestionnaires d'événements et de VBScript. Vous pouvez ensuite utiliser VBScript pour vérifier, par exemple, que tous les caractères ajoutés sont des nombres. Pour davantage d'informations, veuillez vous reporter à Gestionnaires d'événements.
Types de codes-barres compatibles
Le module OCR M-Files est compatible avec les types de codes-barres suivants :
- Code QR
- Data Matrix
- Aztec Code
- EAN-13
- EAN-8
- EAN-5
- EAN-2
- MSI Plessley
- MSI Pharma
- UPC-A
- UPC-E
- Codabar
- Interleaved 2 of 5
- Discrete 2 of 5
- Code 39
- Code 39 Extended
- Code 39 HIBC
- Code 93
- Code 128
- PDF 417
- Postnet
- Postnet 32
- Postnet 52
- Postnet 62
- Patchcode
- UCC-128
- UPCE Extended
- IATA 2 of 5
- Datalogic 2 of 5
- Reverse 2 of 5
- Code 39 (out-of-spec)
- Code 128 (out-of-spec)
- Codabar (out-of-spec)